AWS отключает значительную часть интернета
В понедельник из-за масштабного сбоя в работе AWS были недоступны тысячи сайтов и приложений, а также футбольный матч Премьер-лиги. В этой статье мы расскажем о причинах этого масштабного сбоя и о том, какие уроки можно извлечь из этой ситуации
Понедельник выдался интересным: Signal перестал работать, у Slack и Zoom возникли проблемы, большинство сервисов Amazon также были недоступны. Причиной стал 14-часовой сбой в работе AWS в регионе us-east-1. В этом выпуске The Pulse мы подробнее рассмотрим произошедшее и его причины, а именно:
- Влияние на весь мир. От камер Ring, Robinhood, Snapchat и Duolingo до Substack — сайты и сервисы закрылись тысячами.
- Неожиданные зависимости AWS. Не удалось обновить страницы состояния с помощью продукта Statuspage от Atlassian, матрасы Eight Sleep были фактически недоступны для пользователей, Postman не работал, британские налогоплательщики не могли получить доступ к порталу HMRC, а матч Премьер-лиги был прерван.
- Что стало причиной сбоя? Из-за состояния гонки DNS в DynamoDB, перегрузки Amazon EC2 и проблем с распространением сигнала в сети сбой продлился 14 часов.
- Почему такая зависимость от us-east-1? Такое ощущение, что половина интернета работает на us-east-1 из-за низких цен и высокой пропускной способности. При этом некоторые сервисы AWS сами зависят от этого региона.
Есть такая шутка: когда aws us-east-1 чихает, весь мир простужается. Это самый популярный регион для развёртывания сервисов; многие компании выбирают его по умолчанию. Кроме того, aws-us-east-1 — самый крупный и старый из регионов AWS, и у самой компании там есть несколько зависимых объектов. Сбой в работе всего региона us-east-1 обычно приводит к проблемам в масштабах AWS, которые могут затронуть множество веб-сайтов, приложений и инфраструктурных компаний.
1. Влияние на мировой уровень
В понедельник, 20 октября, сбой в работе в этом регионе начался около 3 часов утра по восточному стандартному времени (9 часов утра по центральноевропейскому стандартному времени) и продолжался в общей сложности 14 часов. Пострадали следующие сайты и приложения:
Сервисы Amazon: Amazon.com работал с перебоями, камеры Ring перестали функционировать, у Prime Video возникли проблемы, Alexa вышла из строя (и будильники пользователей не срабатывали), а сервисы Kindle были недоступны. Проблемы с торговой площадкой Amazon, вероятно, привели к финансовым потерям из-за сбоев в торговле на сайте.
Обмен сообщениями: Signal, Slack и Zoom работают с перебоями. Многие пользователи Signal не смогли войти в систему или отправить сообщения.
Банковское дело и финтех: пострадали клиенты Coinbase, Robinhood, Venmo и британских банков, таких как Barclays, Halifax и Bank of Scotland. Многие клиенты не могли войти в систему во время сбоя, а некоторые пользователи Coinbase не могли торговать криптовалютой.
Некоторые компании, например Robinhood, публично обвинили AWS в том, что компания стала причиной сбоя.
Социальные сети и игры: Snapchat, Duolingo, Reddit, Roblox, Fortnite, Pokémon Go, Clash of Clans, Wordle, Epic Games Store и PlayStation Network — все они пострадали.
Поставщики инфраструктуры: Vercel временно вышел из строя (но восстановился, переключившись на другие регионы), программное обеспечение для рабочих процессов Zapier перестало работать, а онлайн-база данных Airtable стала частично недоступной. Все основные поставщики услуг онлайн-поддержки столкнулись с проблемами: PagerDuty, OpsGenie и incident.io столкнулись с задержками в доставке уведомлений.
Этот информационный бюллетень: Substack вышел из строя и на несколько часов отключил архивы информационных бюллетеней и подкастов The Pragmatic Engineer, а также все остальные публикации Substack.
… и многие другие: из-за сбоя перестали работать тысячи сайтов и приложений. Сервисы совместных поездок (Lyft), авиакомпании (Delta и United), поисковые системы (Perplexity), McDonald’s, Starbucks и многие другие. Последствия были настолько масштабными, что даже действующий сенатор США обвинил AWS в «выведении из строя всего интернета».
2. Неожиданные зависимости от AWS
Во время отключения электроэнергии несколько продуктов неожиданно пришли в негодность.
Statuspage.io не позволяет обновлять статус
Статусная страница Atlassian.io работает в облаке Atlassian, которое пострадало от сбоя в работе AWS, в результатеклиенты Statuspage не могли войти в систему и обновить свои статусные страницы.
Это означало, что на страницах статуса компаний отображался зелёный цвет, хотя на самом деле там был указан текущий сбой! Многие компании используют Statuspage как отдельную систему, не зависящую от их собственной инфраструктуры. Statuspage напрямую зависит от AWS-us-east-1 и не является продуктом для нескольких регионов, что, по-видимому, противоречит цели Statuspage!
Даже сегодня на странице статуса Statuspage не отображается информация о сбое 20 октября, что немного иронично:

Умным матрасам Eight Sleep нет покоя
Одним из заметных сбоев в работе стали матрасы Eight Sleep, которые застревали в одном положении, переставали охлаждаться, а их элементы управления переставали реагировать на команды.

По иронии судьбы, Гильермо Раух, генеральный директор Vercel — компании, которая также пострадала от сбоя, — был разбужен посреди ночи собственным матрасом Eight Sleep, который начал нагреваться. К тому времени, как он встал, команда инженеров Vercel уже устраняла последствия сбоя.
Если матрас становится непригодным для использования во время сбоя в работе AWS, это значит, что он также становится непригодным для использования при обрыве Wi-Fi-соединения или интернета, чего просто не должно происходить с продуктом премиум-класса! Зачем компании Eight Sleep делать матрас доступным только онлайн?
Я подозреваю, что это связано с тем, что они привязывают матрас к ежемесячной подписке SaaS стоимостью 199–299 долларов в год. Компания Eight Sleep позволяет клиентам, которые заплатили за матрас от 2500 до 5000 долларов, пользоваться им без этой подписки, а требование «постоянного подключения», вероятно, помогает предотвратить «взлом» матраса. Но не буду врать: кровать SaaS, которая работает только по подписке, кажется мне немного антиутопичной.
К чести команды Eight Sleep, сейчас они работают над функцией локального управления, чтобы матрасом можно было управлять с помощью приложения через Bluetooth при отключении сети.
Клиент Postman API не работает
Postman — самый популярный клиент API, согласно опросу The Pragmatic Engineer 2025. Он используется для создания и отладки API и представляет собой гораздо более функциональную версию таких инструментов, как curl.
Во время сбоя в работе AWS клиент стал недоступен: сервис перестал работать для клиентов, размещенных в регионе AWS uS-east-1, а общедоступный API postman.com также был недоступен. Европейские клиенты, размещенные в зонах доступности AWS во Франкфурте, не столкнулись с какими-либо перебоями в работе.
Сбой в работе Postman в США удивил многих разработчиков, потому что было логично предположить, что Postman по большей части будет работать локально; в конце концов, этот инструмент предназначен для отправки запросов с вашего компьютера к тестируемому API. Postman объявил за три дня до сбоя, что за несколько дней до него они начали работать над автономным режимом, но на момент публикации эта функция была недоступна — но она появится очень скоро!
Среди популярных альтернатив Postman, работающих в автономном режиме, можно назвать клиент API с открытым исходным кодом Bruno и старый добрый curl — инструмент командной строки.
Британский HMRC
Налоговая и таможенная служба Великобритании была отключена, в результате чего жители страны лишились доступа к налоговым услугам. Этот сбой показал, что британское правительство критически зависит от инфраструктуры США.
Это разоблачение вызвало политический резонанс в Великобритании по поводу того, почему правительство выбирает для своих операций центры обработки данных в США, а не в Великобритании. Это вызывает недоумение, учитывая, что AWS предлагает центры обработки данных в Великобритании: регион aws-eu-west-2 расположен в Лондоне и охватывает три зоны доступности. Вероятно, некоторые из этих зависимостей возникли ещё в те времена, когда у AWS не было центров обработки данных в Великобритании. Тем не менее, несмотря на то, что правительство Великобритании сильно зависит от центров обработки данных в США, это вряд ли можно назвать суверенной операцией. В этом есть нюанс, о котором рассказывается ниже в разделе «Почему мир так зависит от us-east-1?».
Прервана прямая трансляция футбольного матча
Футбольный матч Премьер-лиги в Лондоне между ФК "Брентфорд" и "Вест Хэм Юнайтед" был сорван, когда полуавтоматическая система обнаружения офсайда вышла из строя из-за отключения AWS. В результате официальным лицам матча пришлось вернуться к проверке сообщений о незначительном офсайде на экране, и таким образом нападающему "Брентфорда" было отказано в голе. Редко случается, чтобы отключение дата-центра в США влияло на трансляцию футбола в Премьер-лиге Великобритании и демонстрировало охват AWS различных сфер жизни по всему миру.

Обмен сообщениями Signal зависит от AWS: Signal — это сервис обмена сообщениями со сквозным шифрованием, который считается одним из самых безопасных решений. Компания не раскрывает информацию о том, какую инфраструктуру она использует, но теперь мы знаем, что она, вероятно, в значительной степени зависит от AWS, в частности от региона us-east-1.
Для сквозного шифрования не так важно, какой облачный сервис использует компания, потому что даже если злоумышленник получит доступ к данным на серверах, зашифрованные сообщения, хранящиеся на серверах, не будут представлять особой ценности.
3. Что стало причиной сбоя?
К чести AWS, компания постоянно публиковала обновления на протяжении всего периода отключения. Через три дня после инцидента они выпустилиподробное вскрытие – намного быстрее, чем потребовалось 4 месяца в 2023 году после аналогичного крупного события.
Последний сбой был вызван ошибкой DNS в DynamoDB. DynamoDB — это бессерверная база данных NoSQL, созданная для обеспечения надёжности и высокой доступности. Она гарантирует 99,99% бесперебойную работу в соответствии с соглашением об уровне обслуживания (SLA) при настройке репликации в нескольких зонах доступности (AZ). По сути, при работе в одном регионе DynamoDB гарантирует — и выполняет! — очень высокую доступность с низкой задержкой. Более того, хотя по умолчанию в DynamoDB используется асинхронная согласованность (при чтении может не отображаться фактический статус), для чтения также можно настроить синхронную согласованность (гарантированное отображение фактического статуса).
Все эти характеристики делают DynamoDB привлекательным выбором для хранения данных практически в любом приложении, и многие собственные сервисы AWS также в значительной степени зависят от DynamoDB. Кроме того, DynamoDB всегда выполняет свои обязательства по соглашению об уровне обслуживания, поэтому вопрос часто заключается не в том, зачем использовать DynamoDB, а в том, почему бы не использовать это высоконадежное хранилище данных. Возможные причины отказа от его использования: сложные запросы, сложные модели данных или хранение больших объёмов данных, когда затраты на хранение не оправдывают себя по сравнению с другими решениями для хранения больших объёмов данных.
Во время этого сбоя DynamoDB вышла из строя, и dynamodb.us-east-1.amazonaws.com адрес возвращал пустую запись DNS. Для всех сервисов — внешних по отношению к AWS и внутренних — казалось, что DynamoDB в этом регионе AWS исчезла с лица земли! Чтобы понять, что произошло, нам нужно изучить управление DNS в DynamoDB.
Как происходит управление DNS в DynamoDB
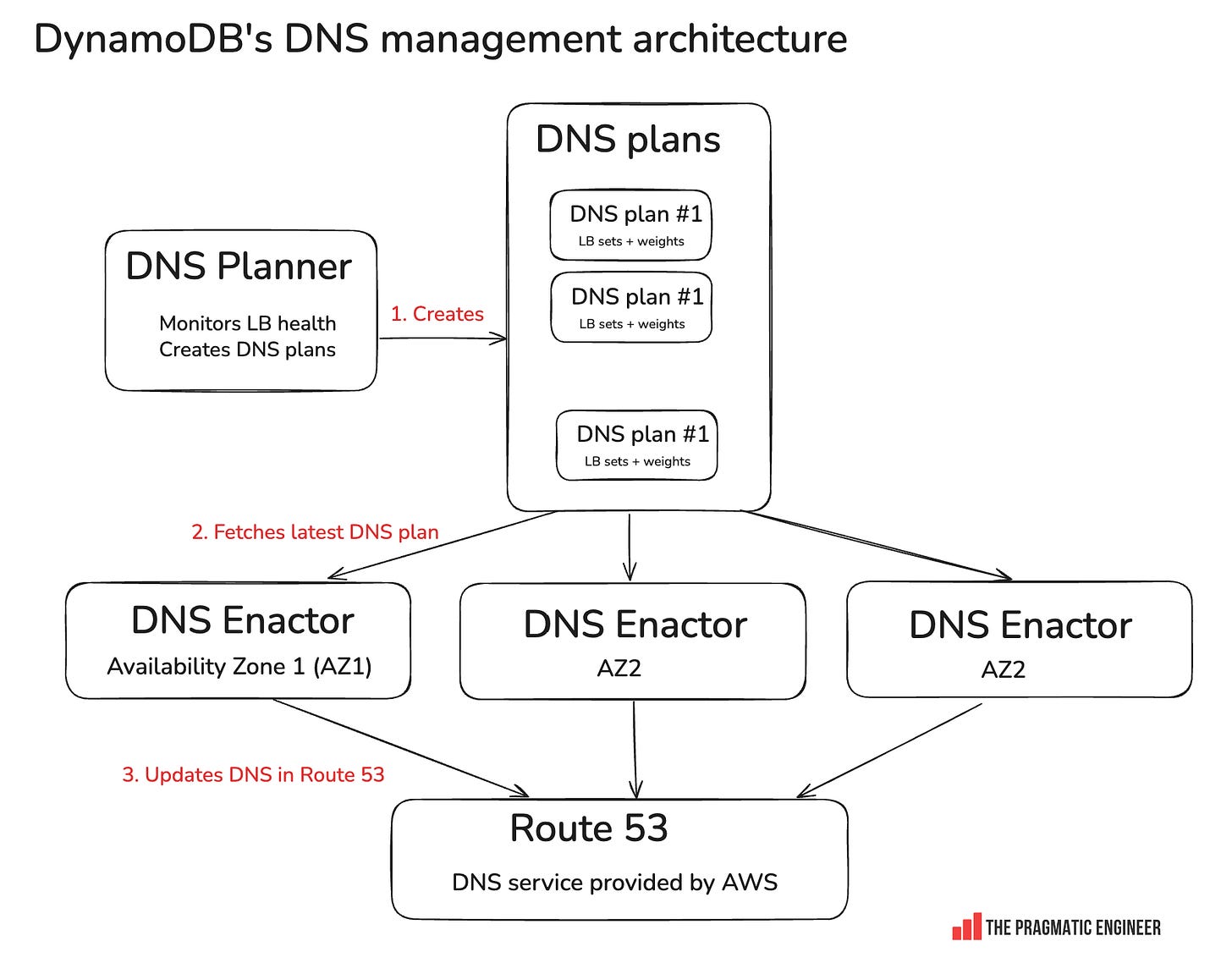
- Планировщик DNS: этот сервис отслеживает работоспособность балансировщиков нагрузки (БН). Как вы понимаете, DynamoDB работает в огромных масштабах, и БН могут легко перегружаться или недозагружаться. При перегрузке необходимо добавлять новые БН, а при недогрузке — удалять их. Планировщик DNS создает планы DNS. Каждый план DNS представляет собой набор БН с указанием веса, определяющего объем трафика для каждого БН.
- DNS Enactor: служба, отвечающая за обновление маршрутов в DNS-сервисе Amazon под названием Route 53. Для обеспечения отказоустойчивости в каждой зоне доступности (AZ) работает по одному DNS Enactor. В регионе us-east-1 есть 3 зоны доступности и 3 экземпляра DNS Enactor.
- Ожидаются состояния гонки: при одновременной работе трёх параллельных DNS-исполнителей ожидаются состояния гонки. Система справляется с этим, предполагая возможную согласованность: даже если DNS-исполнитель обновляет Route 53 «старым» планом, планы DNS согласованы друг с другом. Кроме того, обновление происходит быстро, и DNS-исполнители используют только последние планы из DNS-планировщика.
DynamoDB не работает уже 3 часа
Несколько независимых друг от друга событий привели к отключению DNS в DynamoDB:
- Высокие задержки в DNS Enactor #1. По какой-то причине обновление DNS в одном DNS Enactor заняло необычно много времени. Обычно эти обновления происходят быстро, но не 20 октября.
- Планировщик DNS ускоряет создание планов DNS. Как только обновления DNS стали происходить медленнее, планировщик DNS начал создавать новые планы гораздо быстрее, чем раньше.
- DNS Enactor #2 быстро обрабатывает планы DNS. Пока DNS Enactor #1 применял планы DNS со скоростью улитки, DNS Enactor #2 пробирался сквозь них. Как только он закончил записывать эти планы в Route 53, он вернулся к DNS Planner и удалил старые планы.
Эти три фактора привели систему в нестабильное состояние и опустошили DynamoDB DNS:
- DNS Enactor #1 по незнанию использует старый план DNS. Когда DNS Enactor #2 завершил применение новейшего плана DNS, он вернулся в DNS Planner и удалил все старые планы. Это должно было означать, что другие DNS Enactors не используют старые планы; но помните, что DNS Enactor #1 работал медленно и всё ещё обрабатывал старый план! В результате проверка DNS Enactor #1 была неактуальной.
- DNS Enactor #2 обнаруживает, что используется старый план, и очищает записи DNS. У DNS Enactors есть ещё одна функция очистки: если они обнаруживают, что используется старый план, они удаляют сам план. Удаление плана означает удаление всех IP-адресов для региональных конечных точек в Route 53. Таким образом, DNS Enactor #2 очистил DNS dynamodb.us-east-1.amazonaws.com!
Сбой в работе DynamoDB привёл к отключению всех сервисов AWS, зависящих от сервисов DynamoDB в регионе us-east-1. Из отчёта AWS о причинах сбоя:
«Все системы, которым требовалось подключиться к сервису DynamoDB в регионе Северная Вирджиния (us-east-1) через общедоступную конечную точку, сразу же начали сталкиваться с ошибками DNS и не могли подключиться к DynamoDB. Это касалось как клиентского трафика, так и трафика от внутренних сервисов AWS, которые используют DynamoDB. Клиенты, использующие глобальные таблицы DynamoDB, могли успешно подключаться к своим реплицированным таблицам в других регионах и отправлять запросы к ним, но сталкивались с длительными задержками репликации в и из реплицированных таблиц в регионе Северная Вирджиния (us-east-1)».
Сбой в работе DynamoDB длился около 3 часов; я могу только представить, как инженеры AWS ломали голову над тем, как могли быть удалены записи DNS. В конце концов инженеры вмешались вручную и восстановили работу DynamoDB. Стоит помнить, что восстановление работы DynamoDB могло бы помочь избежать проблемы с «грохочущим стадом», характерной для перезапуска крупных сервисов.
Честно говоря, мне кажется, что при разборе полётов были упущены ключевые детали. Не упомянутые вещи, которые важны для понимания того, что произошло на самом деле:
- Почему DNS Enactor #1 обновлял DNS медленнее, чем DNS Enactor #2?
- Почему DNS Enactor #2 удалил все DNS-записи в рамках очистки? Это действительно не имеет смысла, и, похоже, для этого есть какая-то глубинная причина.
- Похоже, что опережение одним DNS Enactor других участников гонки достаточно легко спрогнозировать. Произошло ли это в первый раз? Если нет, то что случилось после предыдущих подобных инцидентов?
- Самый важный вопрос: как команда устранит эту уязвимость, которая может возникнуть в любой момент в будущем?
Amazon EC2 не работает ещё 12 часов
После восстановления DynamoDB проблемы AWS на этом не закончились. На самом деле проблемы Amazon EC2 только усугубились. Чтобы понять, что произошло, нужно разобраться в том, как работает EC2.
- DropletWorkflow Manager (DWFM) — это подсистема, которая управляет физическими серверами EC2. Считайте, что это «Kubernetes для EC2». Экземпляры EC2 называются «дроплетами».
- Аренда: DropletWorkflow Manager отслеживает аренду каждой капли (сервера), чтобы знать, занят ли сервер и когда он может быть выделен клиенту EC2. DWFM каждые несколько минут проверяет состояние сервера.
Результаты проверки состояния хранятся в DynamoDB, поэтому сбой в работе DynamoDB вызвал проблемы:
1. Срок аренды начал истекать. Поскольку результаты проверки состояния не возвращались из-за сбоя DynamoDB, DropletWorkflow Manager начал помечать капли как недоступные.
2. Ошибки, связанные с нехваткой ресурсов в EC2: поскольку срок аренды большинства ресурсов истек, DWFM начал возвращать клиентам EC2 сообщения об ошибке «нехватка ресурсов». Это означало, что серверы недоступны.
3. Возвращение DynamoDB не помогло: когда DynamoDB снова заработала, можно было обновить статус капель. Но этого не произошло. Из отчёта о вскрытии:
«Из-за большого количества капельниц установка новых капельниц заняла так много времени, что работа не была завершена до истечения срока действия. Для повторной установки капельницы была назначена дополнительная работа. На этом этапе DWFM перешла в состояние переполнения и не могла продвинуться в восстановлении капельниц»
Инженерам потребовалось ещё 3 часа, чтобы найти решение и восстановить работу распределения инстансов EC2.
На устранение ошибок распространения в сети ушло ещё 5 часов. Даже когда внутренняя система EC2 работала без сбоев, инстансы не могли взаимодействовать с внешним миром, и в системе под названием Network Manager возникали перегрузки. Также из отчёта о вскрытии:
«В Network Manager стали наблюдаться повышенные задержки при распространении сетевых данных, поскольку он обрабатывал накопившиеся изменения состояния сети. Хотя новые инстансы EC2 можно было успешно запускать, они не имели необходимого сетевого подключения из-за задержек при распространении сетевых данных. Инженеры работали над снижением нагрузки на Network Manager, чтобы сократить время распространения сетевых конфигураций, и приняли меры для ускорения восстановления. К 10:36 по тихоокеанскому времени [через 11 часов после начала сбоя] время распространения конфигурации сети вернулось к нормальному уровню, и запуск новых инстансов EC2 снова стал осуществляться в штатном режиме.
Окончательная очистка заняла ещё 3 часа. После того как были исправлены все 3 системы — DynamoDB, DropletWorkflow Manager от EC2 и Network Manager, — осталось немного поработать над очисткой:
«Последним шагом на пути к восстановлению EC2 стало полное снятие ограничений на количество запросов, которые были введены для снижения нагрузки на различные подсистемы EC2. Когда количество вызовов API и запросов на запуск новых инстансов EC2 стабилизировалось, в 11:23 по тихоокеанскому времени [через 12 часов после начала сбоя] наши инженеры начали снимать ограничения на количество запросов, работая над полным восстановлением. В 13:50 [через 14 часов после начала сбоя] все API EC2 и новые инстансы EC2 работали в обычном режиме».
Уф, это была та ещё работка! Спасибо команде AWS за то, что справились со всем этим в ту, должно быть, напряжённую ночь. Вы можете прочитать полный отчёт об инциденте здесь, в котором подробно описано влияние на другие сервисы, такие как балансировщик сетевой нагрузки (NLB), функции Lambda, Amazon Elastic Container Service (ECS), Elastic Kubernetes Service (EKS), Fargate, Amazon Connect, AWS Security Token Service и AWS Management Console.
4. Почему такая зависимость от us-east-1?
У AWS есть 38 независимых друг от друга регионов, но когда выходит из строя любой другой регион, последствия не идут ни в какое сравнение с тем, что происходит при возникновении проблем в us-east-1. Это объясняется несколькими причинами:
Несколько глобальных сервисов AWS привязаны к us-east-1
Одна деталь, которая может вас удивить: AWS не сделали несколько своих критически важных сервисов действительно мультирегиональными. Вместо этого панель управления некоторыми сервисами работает исключительно в us-east-1:
Уровень управления доступом к идентификационным данным (Identity Access Management, IAM)является самым важным. Это означает, что такие операции IAM, как создание учётных записей, обновление политик и управление идентификационными данными, зависят от us-east-1, даже если ресурсы расположены в других регионах. Рабочие процессы, зависящие от запросов к политикам учётных записей, могут быть нарушены, поэтому компании, чьи системы зависят от политик IAM, могут оказаться в автономном режиме.
Служба токенов безопасности AWS — ещё одна важная служба, используемая для программного подключения к любому сервису AWS. При использовании устаревшей конечной точки через sts.amazonaws.com, эта конкретная конечная точка не обеспечивает отказоустойчивость в других регионах. Однако при использовании региональных конечных точек сбой в одном регионе не повлияет на работу сервиса в другом. (Спасибо Дэвиду Катберту за исправление в комментариях ниже).
Другие сервисы, работающие исключительно в регионе us-east-1:
Есть сервисы, которые реплицируют данные в другие регионы, но плоскость управления находится в us-east-1. Это означает, что при отключении us-east-1 невозможно внести изменения в конфигурацию этих сервисов.
- Публичный DNS Route 53
- Облачный фронт Amazon
- Менеджер сертификатов Amazon (ACM) для CloudFront
- Усовершенствованный AWS Shield
Большинство из них привязаны к us-east-1 по историческим причинам: us-east-1 — самый старый регион AWS, поэтому сервисы, работающие в одном регионе, обычно запускались там. Добавление полноценной поддержки нескольких регионов для каждого из этих сервисов потребовало бы больших усилий, поэтому для этого должна быть веская бизнес-причина, даже для AWS. Кроме того, из-за высокой нагрузки us-east-1 получает гораздо больше внимания со стороны операторов, что обычно означает, что это очень стабильный регион для работы. И наоборот, когда в us-east-1 идёт дождь, он льёт по всей территории AWS.
Низкие цены, высокая производительность, хорошая задержка
Цены на ресурсы AWS зависят от региона, и исторически сложилось так, что в us-east-1 в Северной Вирджинии цены на инстансы были самыми низкими. С точки зрения задержки сигнала Восточное побережье является идеальным местом для обслуживания всей территории США и Европы. Добавьте к этому самые низкие цены на инстансы, и спрос в этом регионе будет самым высоким.
Чем выше спрос, тем больше AWS будет инвестировать в расширение этого региона. Земля и рабочая сила в Северной Вирджинии дешевле, чем в большинстве других штатов США, поэтому цены за инстанс остаются одними из самых низких во всех регионах, а средняя задержка в США и Европе — самой низкой, что приводит к ещё большему спросу… вы видите, как это превращается в замкнутый круг.
Есть и другие регионы, где цены такие же низкие, как в us-east-1: например, us-west-2, расположенный в Орегоне, предлагает почти такие же низкие цены (спасибо Дэвиду Катберту за поправку в комментариях ниже). Цены на инстансы в более дорогих регионах, таких как Калифорния (us-west-1) или Тоёко (ap-northeast-1), выше, чем в us-east-1, обычно на 15–25 %%
На сегодняшний день us-east-1 является крупнейшим регионом AWS.Он обеспечивает приблизительно 2,5 ГВт мощности, распределённой между 6 зонами доступности (AZ) и 158 центрами обработки данных. Для сравнения: второй по величине регион — us-west-2 в Орегоне, с приблизительно 1,7 ГВт мощности, распределённой между 4 зонами доступности (AZ) и 48 центрами обработки данных.
Если компания выбирает один регион для развёртывания на всей территории AWS, то us-east-1 — довольно практичный выбор с точки зрения цены, задержки и местоположения. А если компания выбирает второй регион для регионального аварийного переключения, то us-east-2, расположенный в Огайо, предлагает те же цены, что и us-east-1, и такую же задержку. Таким образом, основной регион us-east-1 с аварийным переключением us-east-2 также может быть разумным выбором.
Переход с us-east-1 требует времени и может быть сопряжён с трудностями
Крупные технологические компании, работающие на AWS, однозначно будут использовать us-east-1, даже если у них несколько регионов. Низкая задержка и низкая стоимость слишком привлекательны, а этот регион считается одним из самых стабильных. Компаниям, которые готовятся к редким сбоям в работе всего региона, потребуется время для переключения с us-east-1.
Возьмём, к примеру, Vercel, часть инфраструктуры которого находится в us-east-1 и который пострадал от этого сбоя. Vercel был готов к переключению в случае сбоя в регионе. Однако во время обычного переключения 20 октября произошла серия каскадных сбоев, на устранение которых ушло около 2,5 часов:

Пример Vercel доказывает, что подготовка к аварийному переключению на уровне региона работает. Несмотря на то, что у компании возникли проблемы с этим конкретным переключением, они восстановили работу сервиса гораздо быстрее (за 2,5 часа), чем AWS потребовалось для восстановления бесперебойной работы в регионе (14 часов). В отчёте о расследовании Vercel делится более подробной информацией об этом инциденте.
Выводы
В сфере инфраструктуры есть расхожая шутка о том, что «причины самых крупных сбоев всегда кроются в DNS».

В этом есть доля правды: в 2021 году Meta полностью отключилась на 5 часов из-за DNS, а точнее, из-за сообщений BGP, используемых для обновления DNS. Крупный сбой в работе AWS в 2023 году также был вызван состоянием гонки при обновлении DNS.
Почему крупные сбои так часто происходят из-за DNS? Во-первых, интернет работает на DNS: не существует другого широко распространённого протокола для преобразования понятных человеку адресов в IP-адреса.
Другая причина заключается в том, что DNS легко настроить неправильно. Кроме того, при настройке легко допустить ошибку, а на исправление может уйти много времени: настройте неправильные значения времени жизни (TTL) с помощью некорректной конфигурации, и распространяемые значения могут кэшироваться в интернете в течение нескольких часов!
Задержки при распространении — ещё один источник проблем: записи DNS кэшируются на других DNS-серверах и на клиентских устройствах, поэтому неправильные настройки распространяются повсеместно, а на распространение исправлений требуется время.
Наконец, у нас нет хорошего стандартного «инструментария DNS», который помог бы решить проблемы. Каждая компания и команда создают собственные системы проверки изменений DNS, системы аудита для отслеживания изменений и системы разрешений, которые позволяют вносить изменения в DNS только экспертам, поскольку неправильная конфигурация может привести к масштабным сбоям. Это заставляет меня задуматься о том, можно ли создать стартап для разработки продвинутого и надёжного инструментария DNS, ведь сбои в работе DNS происходят уже несколько десятилетий.
Крупным технологическим компаниям необходимо проводить региональные учения по аварийному переключению. Для стартапов и небольших команд разумной стратегией будет использование инфраструктуры в одном регионе — в нескольких зонах доступности. Работа в нескольких регионах сложна и затратна, и имеет смысл прибегать к ней только в том случае, если сбой может привести к значительным финансовым потерям.
Но при поддержке нескольких регионов необходимо отрабатывать аварийное переключение с одного региона на другой. Это был вывод компании Vercel после сбоя и аварийного переключения, которое привело к задержкам. Конечно, для переключения на резервный ресурс требуется время, и легко предположить, что оно наверняка сработает. Но культура регулярного переключения на резервный ресурс или работы при высокой нагрузке — это то, что отличает компании, которые выходят из строя во время редких событий, подобных этому, от тех, которые быстро восстанавливаются и продолжают работать в других регионах или даже с другими поставщиками облачных услуг!
AWS улучшила информирование о крупномасштабных инцидентах, но по-прежнему не раскрывает слишком много внутренних подробностей. Два года назад мы проанализировали как Azure, AWS и GCP справлялись с региональными сбоями. Тогда я сделал следующий вывод о подходе AWS к устранению сбоев:
«AWS: занимает оборонительную позицию. Стремится публиковать как можно меньше публичных отчётов об инцидентах, при этом информируя своих клиентов через менеджеров по работе с клиентами (TAM) и панель мониторинга состояния (PHD.)»
В то время AWS не хотела публиковать результаты расследования сбоя в us-east-1. В конце концов они это сделали после того, как я настойчиво обратился к их команде по связям с общественностью, напомнив им, что отказ от публикации результатов расследования такого серьёзного инцидента противоречит их обязательствам по анализу последствий инцидентов. После долгих препирательств, спустя 4 месяца после инцидента, AWS опубликовала результаты расследования. На этот раз всё было иначе: AWS потребовалось 3 дня и никаких «подталкиваний», чтобы раскрыть подробности причин этого резонансного сбоя.
Тем не менее, мне бы хотелось, чтобы в отчёте о вскрытии были более подробные объяснения того, что на самом деле пошло не так. Cloudflare справляется с этой задачей гораздо лучше, и мне кажется, что AWS упустила ключевые детали о том, что вызвало сбой и почему его было так сложно диагностировать — даже для опытной команды AWS.
В общем, похоже, что-то изменилось в AWS, и на этот раз они стали более открытыми. Какой бы ни была причина, я с радостью воспользуюсь этой возможностью!
Перевод: https://newsletter.pragmaticengineer.com/p/the-pulse-aws-takes-down-a-good-part