Инженерная культура Google: стек технологий (часть 2)
Узнайте, как работает Google, с точки зрения технических специалистов этого технологического гиганта: инфраструктура планетарного масштаба, стек технологий, внутренние инструменты и многое другое
«Каково это на самом деле — работать в Google?» — вот вопрос, который рассматривается в этом мини-сериале. Чтобы узнать подробности, мы поговорили с 25 нынешними и бывшими инженерами-программистами и руководителями инженерных отделов с 4-го по 8-й уровень. Кроме того, мы потратили последний год на исследования: изучали статьи и книги, в которых обсуждаются эти системы. В процессе мы собрали много информации и интересных фактов, которые объединены в этой статье (и мини-сериале). Мы надеемся, что это обеспечит беспрецедентную детализацию по сравнению с тем, что сейчас доступно в интернете.
В первой части мы уже рассмотрели:
Сегодня мы рассмотрим стек технологий, поскольку одним из элементов, который, несомненно, выделяет компанию на фоне других, является то, что Google — это технологический остров со своим собственным инженерным стеком.
- Инфраструктура планетарного масштаба. Внутренняя инфраструктура Google по умолчанию рассчитана на «планетарный масштаб», но Google Cloud не поддерживает его «из коробки»; поэтому большинство инженерных команд используют стек Google PROD, а не GCP.
- Монорепозиторий. Также известный как «Google3», он на 95 % состоит из кода Google, хранящегося в одном гигантском репозитории с миллиардами строк. Разработка на основе магистрали является нормой. Кроме того, монорепозиторий не означает, что у Google монолитная кодовая база.
- Технологический стек. Официально поддерживаются C++, Kotlin, Java, Python, Go и TypeScript с активным использованием Protobuf и Stubby. У Google есть руководства по языковому стилю для большинства языков, которые почти всегда соблюдаются.
- Инструменты для разработки. Набор инструментов для разработки отличается от любого другого рабочего места. Прощайте, GitHub, Jenkins, VS Code и другие известные инструменты: здравствуйте, Piper, Fig, Critique, Blaze, Cider, Tricorder, Rosie и другие.
- Вычисления и хранение данных. Borg, Omega, Kubernetes, BNS, Borgmon, Monarch, Viceroy, Analog, Sigma, BigQuery, Bigtable, Spanner, Vitess, Dremel, F1, Mesa, GTape и многие другие пользовательские системы, на которых работает Google. Этот стек инфраструктуры не похож ни на один другой.
- ИИ. Gemini интегрирован в инструменты для разработчиков и большинство внутренних инструментов, и Google всячески поощряет команды к созданию ИИ, когда это возможно. Команды могут запрашивать ресурсы графического процессора для тонкой настройки моделей, и существует множество внутренних проектов GenAI.
1. Инфраструктура планетарного масштаба
Инфраструктура Google отличается от инфраструктуры любой другой технологической компании тем, что она полностью создана на заказ: не только инфраструктура, но и инструменты для разработчиков. Google это технологический остров, и инженеры, присоединяющиеся к этому технологическому гиганту, могут забыть об инструментах, к которым они привыкли: GitHub, VS Code, Kubernetes и т. д. Вместо этого им приходится использовать собственную версию инструмента Google, даже если есть аналог.
Планетарный масштаб против GCP
Инженеры Google используют термин «планетарный масштаб» для обозначения способности компании обслуживать каждого человека на Земле. Все инструменты компании работают в глобальном масштабе. Это резко контрастирует с Google Cloud Platform (GCP), где нет встроенных возможностей для развертывания в «планетарном масштабе». Можно создавать приложения, которые могут масштабироваться до таких размеров, но это потребует большого количества дополнительной работы. Крупными клиентами GCP, которым удалось масштабировать инфраструктуру GCP до планетарных масштабов, являются Snap, использующая GCP и AWS в качестве облачного бэкенда, и Uber, использующая GCP и Oracle, как подробно описано в «Переход Uber в облако».
Google использует инфраструктуру планетарного масштаба не только для «крупных проектов», таких как поиск и YouTube. На этом стеке под названием PROD создается и развертывается множество новых проектов.
Кстати, корни базы данных Planetscale (база данных Cursor в настоящее время работает на) уходят в Google и его системы «планетарного масштаба». До того как стать соучредителем Planetscale, Сугу Сугумаране работал в Google на YouTube, где он создал Vitess — базу данных с открытым исходным кодом для масштабирования MySQL. Сейчас Сугу работает над Multigres, адаптацией Vitess для Postgres. Я спросил, откуда взялось название Planetscale. Он ответил:
«Впервые я услышал термин «планетарный масштаб» в Google. Я немного посмеялся, когда услышал его, потому что невозможно создать глобально распределённую ACIDбазу данных без компромиссов. Но тогда Vitess уже работал в «планетарном масштабе» на YouTube, с центрами обработки данных во всех уголках мира.Итак, когда мы решили назвать проект PlanetScale, это было смелое заявление, но мы знали, что Vitess сможет его поддержать.
Изначально Planetscale был запущен с использованием облачного экземпляра Vitess и завоевал популярность благодаря своей способности поддерживать крупномасштабные базы данных. Интересно, что амбиции Google в отношении «планетарного масштаба» воплотились в стартапе по созданию баз данных, соучредителем которого стал выпускник Google!
PROD Стек
«PROD» — это название внутреннего технологического стека Google, и по умолчанию все проекты, как новые, так и уже существующие, создаются на базе PROD. Есть несколько исключений для проектов, созданных на GCP, но использование PROD является нормой.
Некоторые сотрудники Google считают, что PROD не должен не должен использоваться по умолчанию, по мнениюодного из штатных инженеров-программистов. Они сказали нам:
«Многие сотрудники Google часто жалуются — и я с ними согласен, — что лишь немногие сервисы действительно должны быть «планетарными» с первого дня! Но сложность создания планетарного сервиса даже на базе PROD на самом деле снижает производительность и время выхода на рынок для новых проектов.Запуск нового сервиса занимает несколько дней, если не недель. Если бы мы использовали более простой стек, настройка заняла бы несколько секунд, и именно столько времени должно уходить на запуск новых проектов, которым, возможно, никогда не понадобится масштабирование! Как только проект наберет обороты, у вас будет достаточно времени, чтобы добавить поддержку в планетарном масштабе или перейти на инфраструктуру, которая это поддерживает.
Создание продуктов для внутреннего использования на базе GCP может быть сопряжено с трудностями. Инженер-программист привел нам такой пример:
«Есть несколько примеров внутренних версий продуктов, созданных на базе GCP, которые действительно обладали совершенно другими функциями или возможностями».Например, внутренняя версия GCP Pub/Sub называется GOOPS (Google Pub/Sub). Для настройки GOOPS нельзя было использовать удобный интерфейс GCP: нужно было использовать файл конфигурации. По сути, у внешних пользователей GCP Pub/Sub гораздо больше возможностей для разработки, чем у внутренних пользователей.”
Нет смысла использовать общедоступный сервис GCP, если уже есть один в PROD. Другой инженер Google сказал нам, что внутреннюю версию Spanner (распределённой базы данных) гораздо проще настроить и контролировать. Внутренний инструмент для управления Spanner называется Spanbob, а также существует внутренняя расширенная версия SpanQSL.
Google выпустила Spanner на GCP как общедоступный сервис. Но если какая-либо внутренняя команда Google использовала Spanner на GCP, она не могла использовать Spanbob — и ей приходилось проделывать гораздо больше работы только для того, чтобы настроить сервис! — и не могла использовать внутренний расширенный SpannerSQL. Поэтому неудивительно, что практически все команды Google выбирают инструменты из стека PROD, а не из стека GCP.
Единственная крупная технологическая компания, которая не использует собственное облако для новых продуктов
Google находится в ситуации, когда ни один из её «основных» продуктов не использует инфраструктуру GCP: ни Поиск, ни YouTube, ни Gmail, ни Google Docs, ни Календарь Google. Новые проекты по умолчанию создаются на PROD, а не на GCP.
Сравните это с Amazon и Microsoft, которые поступают наоборот:
- Amazon: почти полностью на AWS, и все новое создается на этой платформе. Почти все сервисы перешли на AWS. «Современный стек» — это NAWS (Native AWS), и все новые проекты используют его. Остальная часть стека — это MAWS (Move to AWS); устаревшие системы еще не переведены на AWS.
- Microsoft: активное использование Azure, на основе которого строится всё новое. Microsoft 365, Microsoft Teams, Xbox Live, GitHub Actions и Copilot работают на базе Azure. Такие приобретения, как LinkedIn и GitHub, постепенно переходят на Azure, на основе которого по умолчанию строится каждый новый проект.
Почему технические специалисты Google сопротивляются внедрению GCP?
- Поддержка в «планетарном масштабе» не предусмотрена. Обычно PROD выбирают потому, что в случае резкого роста популярности продукта или услуги инфраструктура может расширяться бесконечно без миграции.
- Превосходный опыт разработки с помощью PROD. Spanner — очевидный пример; в целом инструменты, созданные на основе PROD, гораздо удобнее и проще в работе для разработчиков Google.
- Историческое отторжение GCP. 5–10 лет назад было сложно представить, что на GCP можно что-то создать. Тогда в ней отсутствовали некоторые внутренние системы, необходимые для внутренних проектов, такие как аудит и контроль доступа с использованием внутренних систем. Сейчас ситуация изменилась, но отторжение GCP осталось прежним.
Один из нынешних инженеров-программистов Google подытожил:
“Внутренняя инфраструктура соответствует мировым стандартам и, вероятно, является лучшей в отрасли. Я думаю, что многие инженеры Google хотели бы использовать GCP, но внутренняя инфраструктура создавалась специально для них, в то время как GCP более универсальна и ориентирована на более широкую аудиторию”.
Другой инженер-программист из этой компании сказал:
“В конце концов, PROD просто настолько хорош, что GCP по сравнению с ним - ступенька вниз. Это относится к:Безопасность — это то, что есть по умолчанию. GCP требует дополнительных размышлений и работыПроизводительность — добиться хорошей производительности внутреннего стека несложноПростота — внутренняя интеграция не требует особых усилий, в отличие от GCP, где работы гораздо большеОсновная причина использования GCP — это оптимизация для дога, но у этого подхода много недостатков, поэтому команды, которые ищут лучший инструмент, просто используют PROD».
Отсутствие директивы сверху, скорее всего, является ещё одной причиной. Переход с собственной инфраструктуры на облачные сервисы компании — сложная задача! Когда я работал в Skype в составе Microsoft в 2012 году, нам сверху дали указание полностью перевести Skype на Azure. Этой работой занималась команда Skype Data, которая работала со мной в одном отделе. Это был изнурительный и сложный процесс, потому что в то время Azure не могла похвастаться достаточной поддержкой и надёжностью. Но поскольку это был приказ сверху, в конечном счёте всё получилось! Команда Azure уделила первостепенное внимание потребностям Skype и внесла необходимые улучшения, а команда Skype пошла на компромиссы. Без давления сверху этот переход никогда бы не состоялся, поскольку у Skype был целый список причин, по которым Azure была не лучшим выбором в качестве инфраструктуры по сравнению с текущим положением дел.
Google действительно уникальная компания с внутренней инфраструктурой, которую инженеры считают гораздо более совершенной, чем общедоступное облако GCP. Возможно, такой подход также объясняет, почему GCP занимает третье место среди поставщиков облачных услуг и не демонстрирует особых признаков того, что может догнать AWS и Azure. В конце концов, Google не пользуется доверием к своему облаку — не говоря уже о том, чтобы внедрять его по принципу «сверху вниз»! — как это сделали Amazon и Microsoft со своими облаками.
2. Монорепозиторий
Google хранит весь код в одном репозитории под названием monorepo, который также называют «Google3». Размер репозитория поражает — вот статистика за 2016 год:
- 2+ миллиарда строк кода
- 45 000 коммитов в день
- 95%инженеров Google используют монорепозиторий
- 800 000 QPS: количество запросов на чтение в репозитории в пиковые моменты, в среднем 500 000 запросов в секунду в каждый рабочий день. Большая часть трафика поступает не от инженеров, а от автоматизированных систем сборки и тестирования Google.
Сегодня масштабы монорепозитория Google, несомненно, увеличились в несколько раз.
В монорепозитории хранится большая часть исходного кода.Заметными исключениями являются проекты с открытым исходным кодом:
- Android: операционная система для смартфонов от Google
- Chromium: веб-браузер с открытым исходным кодом от Google. Google Chrome, Microsoft Edge, Opera, Brave, браузер DuckDuckGo и многие другие созданы на основе Chromium.
- Go: серверный язык программирования, созданный Google
Интересный факт: эти проекты с открытым исходным кодом долгое время размещались на внутреннем Git-хостинге под названием «git-on-borg» для удобства внутреннего доступа (подробнее о Borg мы расскажем в разделе «Вычисления и хранение данных».) Затем это внутреннее репозиторий было зеркалировано на внешнем сервере.
Разработка на основе магистральной ветки является нормой. Все разработчики работают в одной основной ветке, которая является источником достоверной информации («магистральной веткой»). Разработчики создают краткосрочные ветки для внесения изменений, а затем объединяют их с магистральной веткой. Команда разработчиков Google обнаружила, что использование долгосрочных веток разработки снижает продуктивность. В книге «Разработка программного обеспечения в Google» объясняется:
«Если мы представим незавершённую работу как аналог ветки разработки, это ещё больше укрепит нас во мнении, что работа должна выполняться небольшими порциями и регулярно фиксироваться».
В 2016 году в монорепозитории Google работало более 1000 инженерных команд, и лишь немногие из них использовали долгосрочные ветки разработки. Во всех случаях использование долгосрочной ветки было связано с необычными требованиями, а распространённой причиной была поддержка нескольких версий API.
Подход Google к разработке на основе магистрального кода интересен тем, что это, вероятно, крупнейшая инженерная организация в мире, и важно, что в ней есть большие команды разработчиков платформ, которые поддерживают инструменты для монорепозиториев и системы сборки, позволяющие разрабатывать на основе магистрального кода. Во внешнем мире разработка на основе магистрального кода стала нормой для большинства стартапов и крупных компаний: инструменты, поддерживающие многоуровневые сравнения очень помогают.
Документация часто хранится в монорепозитории, и это может создавать проблемы. Вся общедоступная документация по API для Android и Google Cloud хранится в монорепозитории, а это значит, что к файлам документации применяются те же правила читабельности, что и к коду Google. Google предъявляет строгие требования к читабельности всех файлов с исходным кодом (см. ниже). Однако в случае с внешним кодом примеры обычно не соответствуют внутренним рекомендациям по читабельности намеренно!
По этой причине рекомендуется хранить примеры кода за пределами монорепозитория, в отдельном репозитории GitHub, чтобы избежать проблем с читабельностью (например, если файл с примером называется quickstart.java.txt).
Например, вот старый пример документации, где исходный код находится в отдельном файле репозитория GitHub, чтобы избежать проверки читабельности Google. В новых примерах таких как этот код записывается непосредственно в файл документации, который настроен таким образом, чтобы не вызывать проверку читабельности.
Не весь монорепозиторий доступен каждому инженеру. Доступна большая часть кодовой базы, но некоторые разделы ограничены:
- Файл OWNERS: этот файл содержит список владельцев кода. Чтобы что-то объединить, вам нужно получить одобрение хотя бы от одного разработчика из этого списка. Модель «OWNERS» применяется в проектах с открытым исходным кодом, таких как Android или Chromium.
- Хранилища для конфиденциальных данных: доступ на чтение к конфиденциальным проектам или их частям ограничен. Например, некоторые подсказки в проекте Gemini доступны для чтения только инженерам, работающим над ним.
- Инфраструктурные решения для конфиденциальных проектов: командам, занимающимся инфраструктурой, нужен доступ даже к конфиденциальным проектам, чтобы они могли настроить такие инструменты, как codemod (для автоматического преобразования инструментов). Команды, занимающиеся инфраструктурой, обычно назначают одного или двух специалистов по инфраструктуре, которых добавляют в глобальный список разрешённых пользователей, чтобы они могли видеть эти конфиденциальные проекты и помогать разработчикам с настройкой инструментов и решением проблем.
Архитектура и проектирование систем
В 2016 году менеджер по разработке Google Рэйчел Потвин объяснила, что, несмотря на монорепозиторий, кодовая база Google не является монолитной. Мы спросили у нынешних инженеров, так ли это до сих пор, и нам ответили, что ничего не изменилось:
«Честно говоря, я не вижу особой разницы с организациями, которые используют отдельные репозитории, например AWS. В любом случае у нас есть инструменты для поиска по всему коду, на который у вас есть права». — Инженер-программист 6-го уровня в Google.“Процесс разработки программного обеспечения распределен, а не централизован. Система сборки похожа на Bazel (внутренне она называется Blaze). У отдельных команд могут быть свои собственные цели сборки, которые проходят через отдельный CI / CD ”. – Благодарность сотрудников L6 в Google.
Еще одна крупная технологическая компания, которая с самого начала использовала монорепозиторий — это Meta. Подробнее о ее монорепозитории можно прочитать в Статье о культуре разработки в Meta.
Каждая команда в Google выбирает свой подход к проектированию систем, что означает, что продукты часто имеют разный дизайн! Сходство заключается в инфраструктуреи инструментах разработки, которые используют все системы, а также в низкоуровневых компонентах, таких как Protobuf и Stubby, внутренний gRPC. Ниже приведены несколько общих тем, которые обсуждались с более чем 20 сотрудниками Google:
- Сервисы распространены повсеместно. Google не считает их «микросервисами», поскольку многие из них большие и сложные. Но команды редко ориентируются на монолитную архитектуру. Когда сервис становится слишком большим, его обычно разбивают на более мелкие сервисы, в основном из соображений масштабирования, а не модульности.
- Stubby используется для обмена данными между сервисами. Это стандартный способ взаимодействия сервисов друг с другом; gRPC используется редко и обычно только для внешних сервисов.
Один из нынешних инженеров Google описал это место с архитектурной точки зрения:
«Google похож на множество маленьких соборов, собранных на одном большом базаре».

Эта метафора взята из книги «Собор и базар», где собор — это разработка с закрытым исходным кодом (организованная, нисходящая), а базар — разработка с открытым исходным кодом (менее организованная, восходящая).
Несколько интересных фактов о крупных сервисах Google:
- YouTube раньше был монолитом на Python, но позже был переписан на C++ и Java. Много лет назад каждый релиз проходил 50-часовой цикл ручного тестирования, проводимого удалённой командой контроля качества.
- Поиск Google — это самая большая и монолитная кодовая база. Наличие монолитных кодовых баз — это исключение, а не правило.
- Реклама и облачные сервисы используют всё больше (микро)сервисов.
- Переработка сервисов в микросервисы — это подход, который Google использует в некоторых случаях. Переработка приложения с нуля в микросервисную архитектуру (для обеспечения нужного уровня модульности) требует меньше усилий, чем разделение монолита на части.
3. Технологический стек
Официально поддерживаемые языки программирования
Внутри компании Google официально поддерживает следующие языки программирования. Это означает, что для них существуют специальные инструменты и платформы:
Инженеры могут использовать другие языки, но они не получат специальной поддержки от команд разработчиков платформы.
TypeScript заменяет JavaScript в Google,рассказали нам несколько инженеров. Компания больше не позволяет добавлять новые файлы JavaScript, но существующие файлы можно изменять.
Kotlin становится очень популярным не только в мобильной разработке, но и в серверной. Новые сервисы пишутся почти исключительно на Kotlin или Go, а Java кажется «устаревшей». Переход с Java на Kotlin происходит по инициативе разработчиков, большинство из которых считают Kotlin более удобным в работе.
Для мобильных устройствиспользуются следующие языки:
- Objective C и Swift для iOS
- Kotlin для Android (и Java для устаревших приложений). Кроме того, для Android регулярно используется Rust.
- Dart для Flutter (для кроссплатформенных приложений)
Руководства по языковому стилю существуют в Google, и для каждого языка есть своё руководство. Вот несколько примеров:
- Стиль Google Java — Инструмент форматирования Google Java форматирует код в соответствии с этим стилем
- Стиль Google TypeScript
- Стиль Google Python
- Стиль Google Go
- См. все руководства по языковому стилю Google
Функциональная совместимость и удалённый вызов процедур
Protobuf — это подход Google к обеспечению совместимости, который заключается в работе с разными языками программирования. Protobuf — это сокращение от «буферов протокола»: языково-независимый способ сериализации структурированных данных. Вот пример определения protobuf:
издание = «2024»;лицо , Передающее сообщение {строка name = 1;int32 id = 2;строка email = 3;}
Это можно использовать для передачи объекта Person между разными языками программирования; например, между приложением на Kotlin и приложением на C++.
Интересная особенность собственных API Google, будь то GRPC, Stubby, REST и т. д., заключается в том, что они все определены с помощью protobuf. На основе этого определения создаются клиенты API для всех языков. Таким образом, внутри компании легко использовать этих клиентов и вызывать API, не беспокоясь о базовом протоколе.
gRPC — это современная высокопроизводительная платформа с открытым исходным кодом для удаленных процедурных вызовов (RPC) между сервисами. Компания Google открыла исходный код и популяризировала этот протокол связи, который теперь является популярной альтернативой REST. Самое большое различие между REST и gRPC заключается в том, что REST использует HTTP для удобочитаемого форматирования, в то время как gRPC — это двоичный формат, который превосходит REST за счет меньшего размера полезной нагрузки и меньших затрат на сериализацию и десериализацию. Внутри компании сервисы Google, как правило, взаимодействуют с помощью «внутренней реализации gRPC от Google» под названием Stubby и не используют REST.
Stubby — это внутренняя версия gRPC и её предшественник. Почти все взаимодействия между сервисами осуществляются через Stubby. По сути, у каждого сервиса Google есть API Stubby для доступа к нему. gRPC используется только для внешних взаимодействий, например для внешних вызовов gRPC.
Название «stubby» происходит от того, что в протобуферах может быть определено обслуживание, а заглушки могут быть сгенерированы из этих функций на каждом языке. А от «заглушки» происходит «stubby».
4. Инструменты Dev
В некотором смысле повседневные инструменты Google для разработчиков наиболее наглядно демонстрируют, насколько эта компания отличается от других.
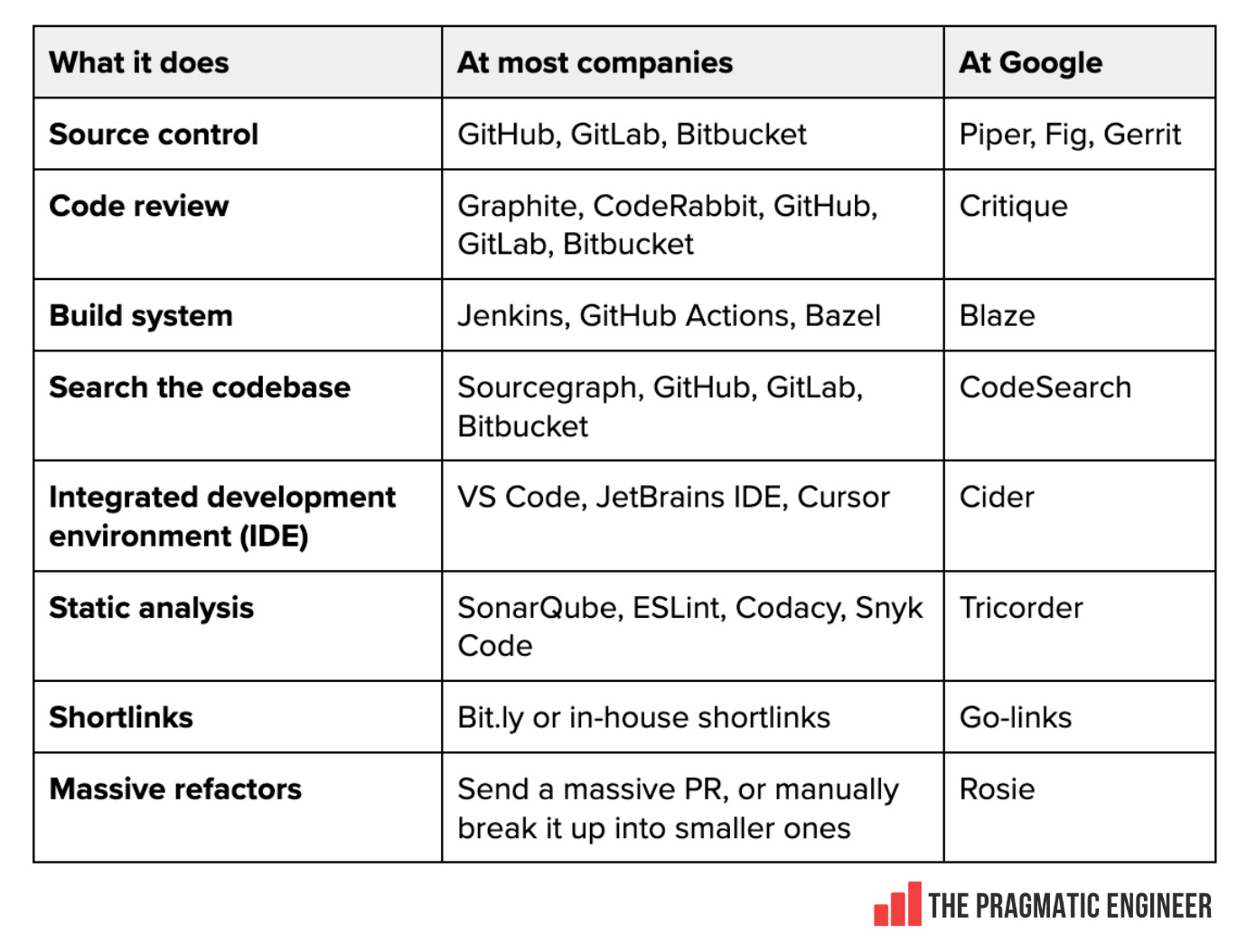
Давайте рассмотрим эти инструменты и то, как они работают в технологическом гиганте:
Контроль версий
Piper — это основное решение Google для контроля версий. В 2020 году оно обрабатывало 60–70 000 коммитов в день и хранило более 80 ТБ метаданных и контента (!). Раньше Piper был построен на Bigtable, а теперь использует Spanner. Он распределён по более чем 10 центрам обработки данных и использует алгоритм Паксоса (который также используется в сервисе распределённых блокировок Chubby) для обеспечения согласованности между репликами.
В первые годы своего существования Google использовала Perforce для контроля версий, но столкнулась с проблемами масштабирования и перешла на другой инструмент в 2012 году. Это показывает, насколько масштабнее деятельность Google по сравнению с другими компаниями: Perforce — это предпочтительное в отрасли решение для контроля версий в крупных кодовых базах. Такие компании, как Nintendo, Ubisoft, Electronic Arts и другие, используют его, потому что Git не поддерживает кодовые базы с большим количеством ресурсов, например игр.
Fig — это новая внутренняя система контроля версий, основанная на Mercurial, по словам нынешних инженеров Google. Многие новые проекты используют Fig, но поддерживаются и Piper, и Fig.
Gerrit — это «интерфейс управления версиями», созданный на основе Git и схожий с системами GitHub и GitLab. Он был открыт компанией Google и использовался в таких проектах, как Chromium и Android. Он поддерживает такие рабочие процессы, как работа со списками изменений (CL) вместо веток.
Проверка кода
Критика — это инструмент для проверки кода от Google. Он работает в веб-браузере и на первый взгляд предлагает те же функции, что и GitHub:

Для многих сотрудников Google любимым инструментом, вероятно, является Critique. Согласно внутренним опросам, уровень удовлетворённости пользователей составляет целых 97 % (!!)
В Critique есть удобные интеграции:
- Если кто-то добавляет комментарий, а вы открываете это рабочее пространство в своей IDE в Cider, вы видите комментарии прямо в IDE и можете ответить на них. Не нужно возвращаться в Critique
- Встроенный поиск и редактор кода
- Поддерживает просмотр файлов по одному
LGTM — это сокращение от «на мой взгляд, выглядит неплохо», и именно так в Critique одобряется CL (запрос на изменение). Это ещё один пример культуры «гуглости»: вместо формального глагола «одобрить» разработчики просто используют LGTM.
Рабочий процесс CL
CL расшифровывается как «список изменений» и является аналогом запросов на вытягивание (pull requests, PR). Несмотря на то, что эти два инструмента похожи, CL отличаются от PR. Вот чем:
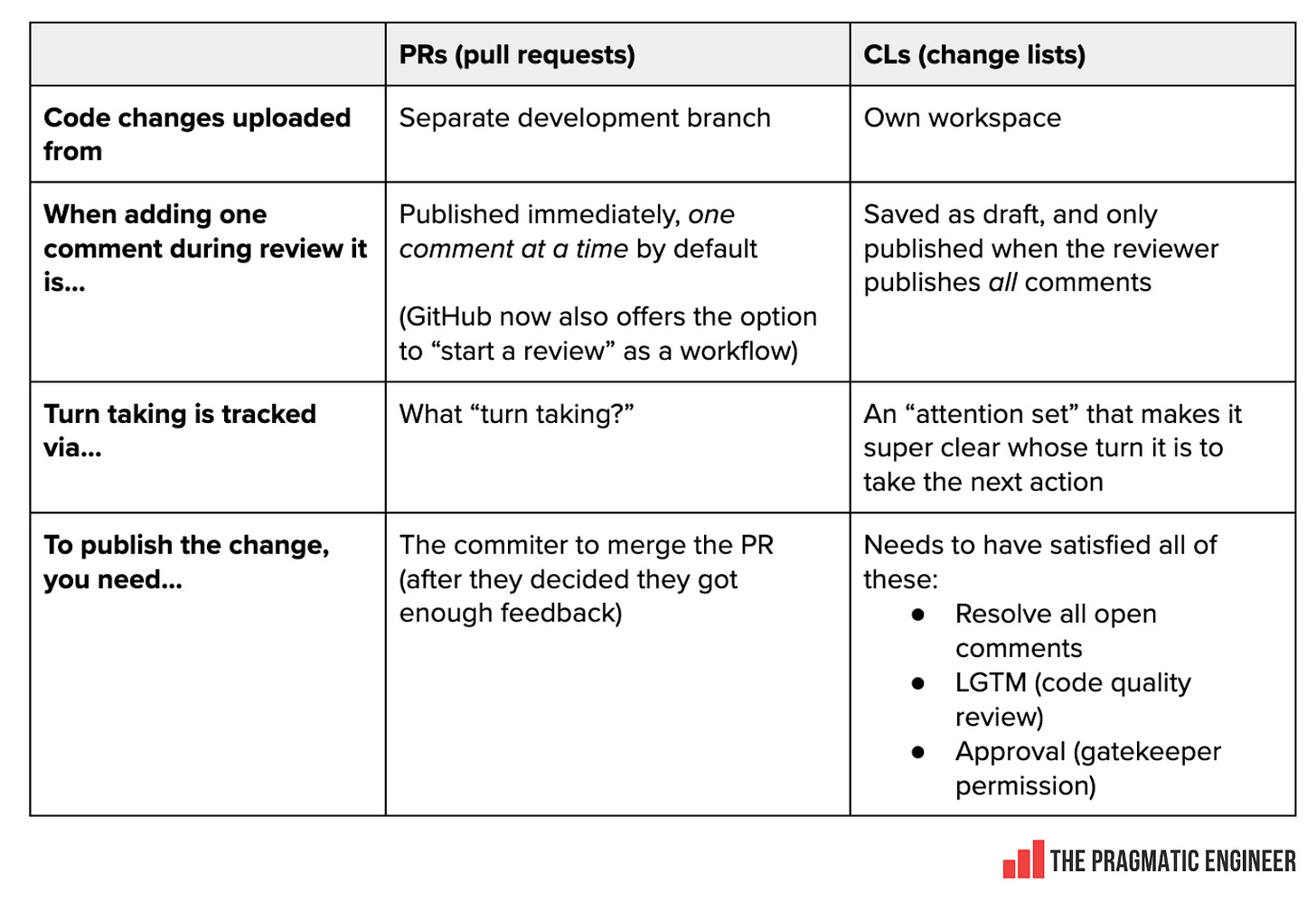
По сути, рабочий процесс CL гораздо более регламентирован, чем рабочий процесс PR. В нем приоритет отдается предоставлению полных, а не частичных комментариев, отслеживанию того, кто выполняет следующее действие, а также строгим проверкам качества, которые должны быть завершены до того, как CL будет отправлен на слияние.
Более подробную информацию о рабочем процессе CL можно найти в этом разделекниги«Разработка программного обеспечения в Google».
Поиск кода
Поиск кода эволюционировал от grep-подобного инструмента, который использовался в Google на ранних этапах, когда он мог найти любое использование слова или фразы, до сегодняшнего дня, когда он может ответить на такие вопросы, как:
- «Где определена эта функция?»
- «Как мне использовать этот класс?»
- «Когда эта переменная была добавлена в кодовую базу?»
Kythe — это инструмент семантического индексирования, который лежит в основе поиска кода. Это инструмент, который позволяет задавать такие вопросы, как «кто вызывает эту функцию?» и «какие классы наследуются от этого класса?»
Поиск кода оптимизирован для чтения кода, а также для понимания и изучения кодовой базы в больших масштабах. Он в значительной степени опирается на облачный сервер для поиска контента и разрешения перекрестных ссылок.
Функция поиска кода позволяет осуществлять поиск кода в проектах с открытым исходным кодом, таких как поиск кода для Android и других проектах. Внутренняя функция поиска кода имеет гораздо больше интеграций, чем доступные извне, например поиск кода для Android.
Вместе с Critique Code Search является одним из самых популярных внутренних инструментов Google. Вот как его описали два нынешних и бывших сотрудника Google:
«Инструмент для поиска кода настолько хорош, что для меня он был чем-то вроде LLM-lite: я использовал его как систему поиска кода».
Sourcegraph — это инструмент для поиска кода, созданный на основе Code Search и предоставляющий возможности «поиска кода» для многих компаний. По словам нескольких инженеров Google, которые используют оба инструмента, в наши дни Sourcegraph по функциональности не уступает Code Search. Мы подробно изучили инженерную культуру Sourcegraph.
Инструменты для поиска кода на базе искусственного интеллекта также упростили воспроизведение «волшебства поиска кода» от Google. Один из сотрудников Google так охарактеризовал поиск кода:
«Мне кажется, что Sourcegraph и другие компании догнали нас в этой области — на самом деле они даже немного превзошли возможности Code Search. Это связано с тем, что в команде Code Search меньше сотрудников, а также с тем, что Code Search в настоящее время не использует поиск кода на основе искусственного интеллекта».
Система сборки
Blaze — это декларативная и распределённая система сборки от Google, созданная специально для монорепозитория. Таким образом, она предназначена для работы в планетарном масштабе. Она использует файлы BUILD для декларативного описания сборок, а также распределена и кэширована на нескольких компьютерах. Шаги сборки «герметичны», то есть зависят только от заявленных входных данных. Они также детерминированы, что означает надёжность системы сборки в целом.
Bazel — это внешняя версия Blaze с открытым исходным кодом, и надёжность является её важной характеристикой, как разработчики программного обеспечения в Google обсуждают:
«Многие старые системы сборки пытаются найти компромисс между скоростью и корректностью, прибегая к упрощениям, которые могут привести к сбоям в сборке. Основная цель Bazel — избежать необходимости выбирать между скоростью и корректностью, предоставляя систему сборки, которая гарантирует эффективную и стабильную сборку кода».
Подробнее о системах сборки в Google и Bazel читайте в главе Системы сборки и философия сборки в вышеупомянутой книге.
В нескольких проектах Google используются разные системы сборки:
- Soong: система сборки используется в Android
- GN: используется в Chromium
- Gradle: используется в AndroidX (набор библиотек с открытым исходным кодом, созданных для Android)
Облачные среды разработки
CitC (Clients in the Cloud) — это инструмент, который позволяет создавать виртуальные рабочие пространства без необходимости извлекать код или хранить его на компьютерах разработчиков, как и в других облачных средах разработки. Подробнее об этом в подробном обзоре облачных сред разработки.
Fig — это преемник CitC, который большинство разработчиков используют для виртуальных рабочих пространств.
IDE
Cider — это интегрированная среда разработки от Google, которой пользуется большинство разработчиков. Она основана на VS Code и выглядит так же, за исключением того, что она хорошо интегрирована с внутренними системами Google, такими как:
- Критика (проверка кода)
- Blaze (инструмент для сборки)
- Гитара (сквозное тестирование с использованием реальных систем)
- TAP (платформа автоматизации тестирования, непрерывная сборка от Google)
- Tricorder (статический анализ)
- CodeSearch (инструмент для поиска кода)
Инженер Google привёл нам пример того, насколько всё там взаимосвязано:
«Очень легко получить ссылку на CodeSearch, которая ведёт на строку, открытую в Cider. Затем вы можете поделиться этой ссылкой, и она откроет Cider на той же строке для всех остальных. Так что это отличный инструмент для обмена вопросами или кодом, который вы просматриваете».
Несколько лет назад Cider был веб-версией IDE с гораздо меньшим количеством возможностей и меньшим объёмом внутреннего использования. После перехода на форк VS Code объём внутреннего использования значительно увеличился.
Масштабный рефакторинг
Rosie — это инструмент для крупномасштабного рефакторинга, который очень полезен, учитывая строгие правила проверки кода в Google. Он может разбивать крупные изменения в коде на более мелкие части. Эти более мелкие части можно тестировать, проверять и отправлять на доработку независимо друг от друга. При разбиении учитывается авторство кода. Инженер L4 объяснил нам, почему они любят Rosie:
«Как разработчику инфраструктуры, вам часто приходится вносить масштабные изменения (кодовые моды) во всё репозиторий. Из-за файла OWNERS внесение таких изменений в виде одного большого коммита вызывает раздражение из-за большого количества необходимых согласований.Рози возьмёт ваш огромный CL с сотнями или тысячами изменённых файлов и разделит его на более мелкие части, которые будут отправлены отдельным командам.
Статический анализ
Tricorder — это инструмент статического анализа от Google. Инженер, работавший над ним, объясняет:
«Tricorder — это инструмент для статического и программного анализа, который запускает линтеры и анализаторы, тесно интегрированные с любой другой системой разработки:Запуск при проверке кодаПри развертыванииПри каждом коммите (так называемом «снимке»).Это платформа по принципу «подключи и работай», на которой команды могут создавать собственные анализаторы кода и определять предварительные условия для их запуска.
Команда попыталась открыть исходный код версии Tricorder под названием ShipShape, но этот проект сейчас заархивирован. Один из инженеров рассказал нам, что из-за разнообразия систем сборки во внешнем мире сделать Tricorder таким же полезным для других компаний, как для Google, гораздо сложнее.
Более подробную информацию о Tricorder можно найти в этой статье.
Перейти по ссылкам
В Google просто введите «go/что угодно», чтобы перейти по быстрой ссылке. Это полезная функция, и многие другие компании создали аналогичную функцию быстрых ссылок, например Stripe со своим инструментом go.
Теперь есть даже сервис под названием GoLinks, который реализует эту простую, но полезную идею!
5. Вычисления и хранение данных
Google расширила свою инфраструктуру до глобального масштаба раньше, чем любая другая технологическая компания. В конце 1990-х — начале 2000-х годов большинство технологических компаний приобретали дорогие и большие мейнфреймы для масштабирования своего парка серверов. В отличие от них, Google создавала вычислительные системы и хранилища на базе стандартного оборудования. Для этого им нужно было создать новые типы программного обеспечения для управления парком стандартного оборудования в невиданных ранее масштабах. Поэтому неудивительно, что у Google уникальная, специализированная программная инфраструктура.
Borg и связанные с ним системы
Borg — это система, которая управляет физической инфраструктурой Google. Borg управляет кластерами из десятков тысяч машин и выполняет на них сотни тысяч заданий. Вот как в статье 2015 года кратко описывается высокоуровневая структура Borg:
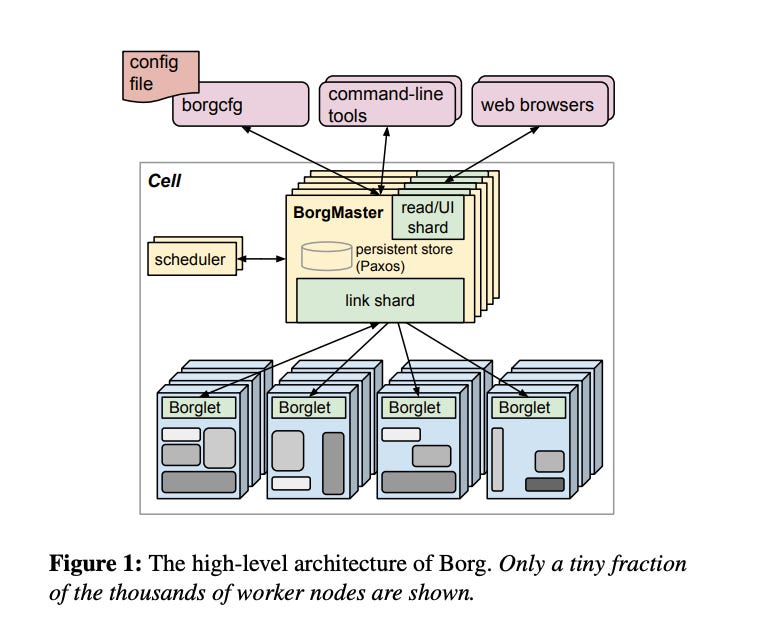
Borg обеспечивает работу всех крупных приложений Google планетарного масштаба, таких как Поиск, Gmail и Реклама. Но и небольшие приложения часто начинают работу с Borg. Например, он используется даже для запуска простых блокнотов на Python. Borg является частью технологического стека PROD, поэтому начать работу с ним внутри компании довольно просто.
Омега был исследовательским прототипом, созданным на основе знаний о Борге с целью его усовершенствования. По сравнению с Боргом он был более гибким и ориентированным на транзакции. В итоге система не получила широкого распространения внутри компании.
Kubernetes был создан компанией Google как проект с открытым исходным кодом на основе разработок Borg и Omega. По сей день Google использует Borg, но Kubernetes стал ведущим в отрасли решением для управления контейнерами. Подробнее об истории Kubernetes мы рассказываем в выпуске подкаста The Pragmatic Engineer, Как устроен Kubernetes.
BNS — это «внутренний DNS» Google. Это сокращение от «Borg Naming Service». BNS использует уровень абстракции над IP-адресами, а Borg использует эту абстракцию для распределения задач между машинами. Вот как в книге Google SRE объясняется как работает BNS:
«Вместо использования IP-адреса и номера порта другие процессы подключаются к задачам Borg через имя BNS, которое преобразуется в IP-адрес и номер порта с помощью BNS. Например, путь BNS может выглядеть так: /bns/<кластер>/<пользователь>/<название задания>/<номер задачи>, что соответствует <IP-адрес>:<номер порта>».
Один из нынешних инженеров Google объяснил необходимость BNS:
«DNS считается ненадёжным и неспособным обновляться так быстро, как того требуют внутренние сервисы Google. Поэтому для привязки сервисов к сетевым протоколам и конечным точкам используется совершенно отдельная система».
Боргмон сокращение от «Борг Мониторинг». Он предназначен для отслеживания работоспособности запущенных сервисов и существует с первых дней существования Google.
Prometheus — это, по сути, «Боргмон для другой работы». Это решение для мониторинга с открытым исходным кодом, разработанное компанией SoundCloud в 2012 году по мотивам Borgmon. Prometheus часто используется вместе с Grafana с открытым исходным кодом для создания платформ мониторинга. Именно эту комбинацию использовала компания Shopify, отказавшись от Datadog в пользу собственной платформы мониторинга.
Monarch — это усовершенствованная версия Borgmon, которая заменила Borgmon для мониторинга многих крупномасштабных рабочих нагрузок в Google. Вот несколько интересных фактов о Monarch:
- Поставляется с базой данных временных рядов планетарного масштаба в памяти
- Используется для мониторинга показателей во всей инфраструктуре Google
- Горизонтально масштабируемый
- Включает поддержку графиков
Наместник является преемником Монарха и часто используется для наблюдения за узлами Борга.
Analog — это внутренний инструмент логирования для Borg.
Sigma — это инструмент для управления конфигурацией кластера в Borg.
Хранение
Вполне вероятно, что Google хранит самый большой объём данных среди всех компаний в мире. В 2015 году только в Gmail хранилось несколько эксабайт данных (1 эксабайт = 1 миллион терабайт), а в 2025 году на YouTube будет размещено более 5 миллиардов видео. Так что можно с уверенностью сказать, что сегодня компания хранит сотни эксабайт данных, если не больше. В сложившихся обстоятельствах вполне понятно, что она разработала несколько собственных решений для хранения данных.
Внешние услуги
BigQuery — это бессерверное облачное хранилище данных, доступное в Google Cloud, альтернатива Snowflake или Amazon Redshift. Оно доступно в GCP с 2011 года.
Bigtable — это сервис баз данных NoSQL с низкой задержкой, совместимый с Cassandra и HBase. Google вывел Bigtable на внешний рынок в 2015 году, и теперь его можно использовать на GCP.
Spanner является базой данных по умолчанию в большинстве сервисов Google. Это глобально распределённая база данных, и в 2017 году Google сделал Spanner общедоступным; он доступен в Google Cloud.
Vitess — это решение для масштабирования и управления большими кластерами баз данных MySQL. Оно было создано в 2010 году для решения проблем с MySQL, с которыми столкнулся YouTube, и успешно справилось с этой задачей. YouTube по-прежнему активно использует Vitess. В 2018 году проект стал открытым.
Услуги только для внутренних пользователей
Dremel раньше был «внутренним эквивалентом» BigQuery. Сейчас это устаревшее название для внутреннего стека технологий бизнес-аналитики, который используется реже.
F1 заменила Dremel в качестве распределённой реляционной базы данных Google. F1 была изначально создана для поддержки бизнеса AdsWords, и её целью было создание базы данных, сочетающей в себе высокую доступность, масштабируемость систем NoSQL, таких как Bigtable, а также согласованность и удобство использования традиционных баз данных SQL. Она построена на базе Spanner.
Mesa — это распределённая база данных, предназначенная для аналитики в реальном времени и составления отчётов по рекламе.
GTape раньше была системой резервного копирования Google с использованием физических носителей. В 2011 году GTape всё ещё использовалась для восстановления Gmailпосле сбоя, повлекшего за собой потерю данных. Нынешние инженеры Google, с которыми мы общались, не уверены, используется ли GTape до сих пор или её заменило другое решение для резервного копирования.
Другие пользовательские инфра-инструменты
У Google есть сотни внутренних инструментов, в том числе несколько интересных:
- BeyondCorp. Внутренняя система безопасности Google с нулевым доверием, используемая вместо VPN. Каждый запрос проверяется, поскольку предполагается, что сеть ненадежна. Аутентификация происходит через единый вход Google, после чего выполняется проверка устройства. BeyondCorp была выведена за пределы компании в 2020 году.
- Dapper: распределённая система отслеживания. Подробнее.
- Chubby: распределённая служба блокировки и координации для выбора лидера и хранения метаданных. Использует алгоритм Паксоса. Подробности.
- B4: Частная программно-определяемая глобальная сеть Google. Подробности.
- Devsite: внутренняя система для создания общедоступных страниц документации. Создана на Django (веб-фреймворк на Python).
- Специальное оборудование. Google также производит собственное специализированное оборудование, такое как серверы, сетевые устройства и даже чипы. Примером может служить облачный тензорный процессор (TPU, ускоритель искусственного интеллекта), разработанный в сотрудничестве с Broadcom.

Инструменты, которые помогают инженерам запускать сервисы:
- Серверная платформа: Универсальная внутренняя платформа для запуска сервиса Stubby со всеми необходимыми компонентами, такими как определение владельцев, CI/CD, мониторинг и т. д. Это стало необходимостью, так как стек технологий Google усложнился. Преимущество серверной платформы в том, что она скрывает многие сложности сервисов Google. Однако из-за этого инженеры перестали понимать, к каким платформам подключается сервис, чтобы всё работало.
- Boq: платформа для микросервисов, которая берет на себя большую часть работы по мониторингу, развертыванию, авторизации, аутентификации, балансировке нагрузки, интеграционному тестированию и составлению сервисов.
У Google так много собственных инструментов, что для поиска инструментов существует собственный инструмент. Есть внутренний сайт для поиска инструментов, поддерживающих определенный стек технологий, потому что даже внутри компании сложно уследить за всеми создаваемыми и устаревшими системами!
Кстати, об устаревании. Возможно, вы заметили, что Google постоянно выпускает новые версии своих инструментов (например, Borgmon → Monarch → Viceroy.) Есть старая как мир шутка о том, что в Google есть только два типа систем: устаревшие и те, что находятся в разработке.

6. ИИ в Google
В 2017 году компания Google изобрела трансформеры — основную концепцию больших языковых моделей — и создала одну из самых мощных моделей искусственного интеллекта под названием Gemini. Она используется в большинстве общедоступных продуктов, таких как Workspace, Gmail и Search. Разумеется, компания уже интегрировала Gemini во многие свои внутренние системы. Cider, Critique и CodeSearch имеют интеграцию с искусственным интеллектом, которая позволяет делать следующее:
- Автодополнение кода (довольно «базовый» вариант использования), а также многострочное автодополнение кода
- Попросите ИИ внести изменения в текущий файл.
- Задавайте вопросы о кодовой базе/текущем файле
- Генерировать тесты
- Попросите ИИ добавить комментарии к коду в CLs
- Когда код вставляется в Cider, он автоматически адаптируется под текущий контекст. Разработчики, с которыми мы общались, считают это очень полезным
По словам инженеров, возможности искусственного интеллекта в Cider всё ещё уступают возможностям Cursor. Но в Cider можно добавлять сочетания клавиш для пользовательских подсказок, чего нет в Cursor.
Похоже, что подход Google к инструментам для написания кода на основе ИИ заключается в том, чтобы сначала завоевать доверие. Похоже, что команда разработчиков инструментов на основе ИИ уделяет первостепенное внимание выпуску действительно эффективных функций, а не недоработанных функций, которые могут ассоциироваться с ненадёжностью ИИ.
Поисковая система MOMA — это внутренняя система базы знаний, которая выполняет поиск по всем внутренним документам. Естественно, она уже как минимум два года интегрирована с искусственным интеллектом. Мы слышали, что поначалу она часто выдавала ложные результаты, но с тех пор ситуация значительно улучшилась.
Внутренние модели Gemini: для внутреннего использования доступны различные модели Gemini, в том числе большие и маленькие модели Gemini, модели с настроенными инструкциями, мыслящие модели и экспериментальные модели. Эти модели размещены на серверах, к которым можно обращаться с помощью внутренних инструментов, таких как блокноты Python, чтобы изучить их возможности. Разумеется, использование этих моделей не ограничено по стоимости.
Игровая площадка LLM: похожа на игровую площадку для разработчиковOpenAI, которая появилась раньше. Доступны различные модели и форматы Gemini, с которыми можно экспериментировать.
Ресурсы графического процессора: Графические процессоры для размещения пользовательских моделей с тонкой настройкой или ресурсы для тонкой настройки моделей обычно выделяются для каждой команды. Мы неоднократно слышали жалобы на то, что время ожидания доступа к графическим процессорам довольно велико и это становится узким местом.
Тестирование внутренних продуктов:приложение Gemini и функции искусственного интеллекта Google Workspace тестируются внутри компании перед выпуском для широкой публики.
NotebookLM: внешне представленный продукт, который позволяет «общаться» с загруженными текстовыми, аудио- и другими ресурсами. Он очень популярен в Google: мы слышали о том, что в него загружают все документы с требованиями к продукту, а затем задают вопросы по ним.
Внутренний список всех инструментов ИИ с примечаниями по конфиденциальности: внутри компании Google перечисляет все свои инструменты с поддержкой ИИ и уровни конфиденциальности, которые они поддерживают. Например, некоторые инструменты могут быть связаны с конфиденциальными документами Google, а другие — с возможностью загрузки только неконфиденциальных документов, если инструмент может вести журнал, из которого могут просочиться конфиденциальные данные.
Рой внутренних проектов GenAI
По словамсотрудника L6, который поделился этим наблюдением, многие команды создают продукты GenAI, чтобы получить финансирование:
«В Google разрабатывается множество инструментов GenAI для конкретных организаций и команд. Руководству это нравится. Как ни странно, в наши дни это отчасти помогает получить больше финансирования».
Я понимаю, почему Google поощряет проекты в области генеративного искусственного интеллекта и выделяет сотрудников для поддержки перспективных проектов:
- В худшем случае инженеры начинают работать с ИИ напрямую. Создавая ИИ-решения, они все становятся ИИ-инженерами, что само по себе ценно!
- В некоторых случаях может быть создан новый продукт, который Google позже выпустит в открытый доступ. NotebookLM — пример такого продукта.
Наконец, если проект с использованием ИИ не имеет смысла, то ничего страшного не произойдёт. Google — очевидно, очень прибыльная компания, поэтому команда, потратившая месяц или два на проекты с использованием ИИ, которые не увенчались успехом, не понесёт больших убытков.
Этот «рой GenAI» и стимулирование команд к созданию ИИ-решений немного напоминают мне о политике Google в отношении 20% проектов. До начала 2010-х годов всем инженерам Google выделялся один день в неделю (20% рабочего времени) на создание всего, что они хотели, что привело к появлению таких проектов, как Gmail, Google News и AdSense. Google в целом отказался от этой политики, хотя в некоторых подразделениях компании она всё ещё действует. Карикатурист Ману Корнет работал в Google, когда это решение было отменено, и считал, что это вредит инновациям:

GenAI создаст новые категории программного обеспечения, и, на мой взгляд, Google возвращает «масштабные инновации», поощряя любые проекты, связанные с искусственным интеллектом. Это вполне объяснимо, поскольку компания может потерять позиции на рынке, если не позволит своим командам создавать решения на основе ИИ.
Выводы
В технических кругах Google считается золотым стандартом в области внутренних инструментов для разработчиков и, наоборот, примером того, что происходит, когда всё в технологическом стеке сделано на заказ.
Borg, Piper, Critique и другие инструменты работают намного лучше в целом, чем инструменты для разработки, к которым имеет доступ большинство инженеров на своих рабочих местах. С другой стороны, они настолько хороши, что инженеры Google не хотят использовать публичный GCP и предпочитают работать с внутренним стеком инфраструктуры. В случае с распределёнными базами данных, такими как Spanner, они всё равно будут использовать внутреннюю версию, а не публичную!
Мы подробно рассказали о пользовательских инструментах, которые есть у инженеров технологического гиганта. Возможно, это покажется вам чрезмерным, но мы хотели дать вам рекомендации и объяснить, почему Google решил создать так много пользовательских инструментов.
В следующей статье этой серии мы расскажем о карьерном росте, внутренней мобильности и дадим несколько советов о том, как добиться успеха в такой компании, как Google.
Если вам есть что сказать по темам, затронутым в этой статье, оставьте комментарий ниже.
Перевод: https://newsletter.pragmaticengineer.com/p/google-part-2